This article explains debugging issues regarding missing data in the Analytics Power BI reports. There can be multiple reasons for missing data and these are explained, step-by-step.
Troubleshooting Data in Analytics
Troubleshooting Data in Analytics
Azure Data Factory
If the Power BI report templates are completely blank when you have connected them to Analytics data warehouse and loaded data, then the first thing you need to make sure of is that the Initial load of the data using the Azure data factory (ADF) has been run successfully and that other subsequent runs of Scheduled run pipeline are also running without errors.
It is very important when setting up Analytics, that the Initial load pipeline is triggered and allowed to finish before any other pipeline is triggered. It is also very important to not schedule more than one Scheduled run pipeline at a time because that can cause duplication of data, which causes issues with merging data into the fact and dimension tables.
Check for Initial load completion and that all pipelines are running
The best way to check if the ADF has any errors is to login to the Azure portal, find your data factory and press “Launch studio” which opens in a new browser tab.

In the ADF studio you should see a few options on the left side of the screen. One of the options is the monitor. Press the monitor and it should show you the log for the ADF pipeline runs in the last 24 hours. You might need to adjust the filter if it has been a long time since you set up Analytics.
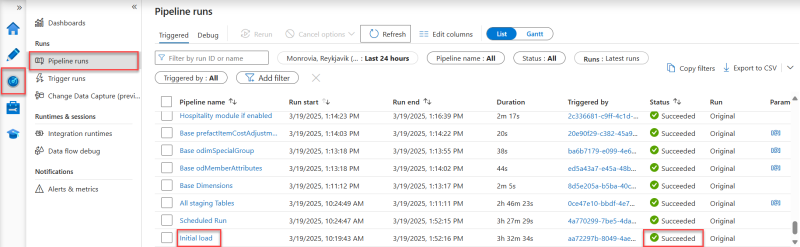
If the Initial load pipeline and subsequent Scheduled run pipelines have status Succeeded then the issue does not lie with the data factory. You can move on to the next section about checking whether the Troubleshooting Data in Analytics have data and how to troubleshoot.
If you can not find any trace of the Initial load or Scheduled run pipelines being run, then you should run Factory reset pipeline to reset the data warehouse completely, and then refresh the report where you could not see any data after the pipeline has finished successfully.
If any of the pipelines have the status Failed, you need to figure out where the error is coming from. How to do this is explained in the error tracing sections below.
When there is an error in the Azure Data Factory (ADF), it is very helpful to look at the Monitor view in Azure Data Factory studio in the Azure portal.
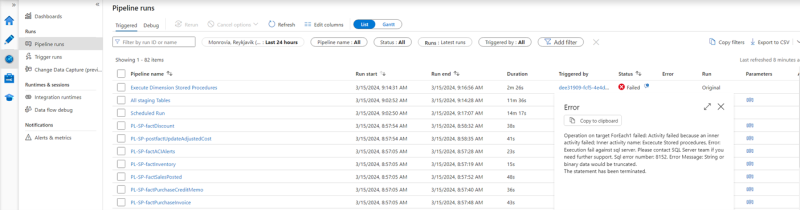
Here we for example have an error in the Scheduled Run, more precisely in the part which executes the dimensions stored procedures.

But how do we find the root cause of the error? If we click the message bubble next to the Failed status, we can see that there was an SQL error in one of the procedures, but we don’t know which one.
To find out which procedure you must click on the “Execute Dimension Stored Procedures” line and then you should see a more detailed log like the one below.
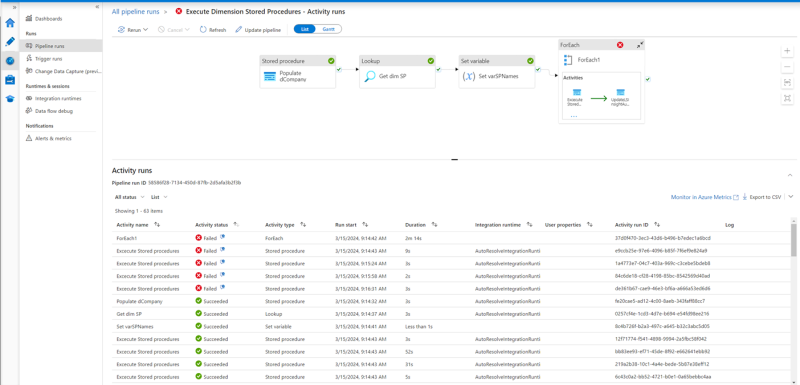
As you can see there are multiple failed steps in the log, the ForEach1 error is because one of the Execute Stored procedures steps failed.
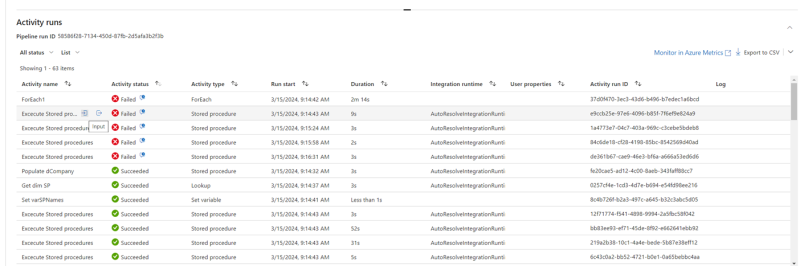
To see which procedure is causing the error, you can press the Input sign which should appear if you hover the mouse over the Execute stored procedure line.
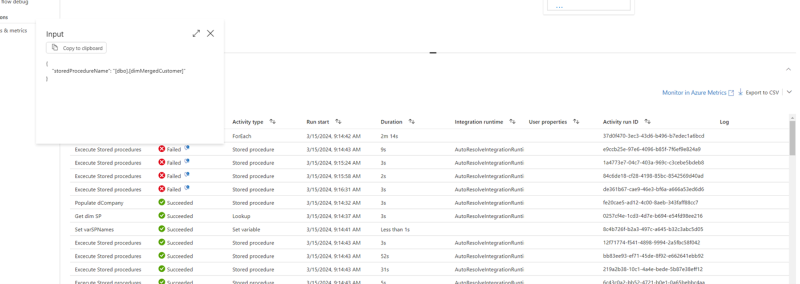
This is the error that you need to send with your request for support. On this level you can also click the message bubble to read the error message and copy the message into the support request and send it through the support portal and you get help with the next steps.
Another type of error that sometimes happens in the Azure data factory - fact table pipelines is a merge error. For these errors you can see the error immediately when hovering over the pipeline run list in the monitor tab and it looks like the example below.
Operation on target Execute Stored Procedure failed: Failure happened on 'Source' side. ErrorCode=SqlOperationFailed,'Type=Microsoft.DataTransfer.Common.Shared.HybridDeliveryException,Message=A database operation failed with the following error: 'The MERGE statement attempted to UPDATE or DELETE the same row more than once. This happens when a target row matches more than one source row. A MERGE statement cannot UPDATE/DELETE the same row of the target table multiple times. Refine the ON clause to ensure a target row matches at most one source row, or use the GROUP BY clause to group the source rows.
Warning: Null value is eliminated by an aggregate or other SET operation.',Source=,''Type=System.Data.SqlClient.SqlException,Message=The MERGE statement attempted to UPDATE or DELETE the same row more than once. This happens when a target row matches more than one source row. A MERGE statement cannot UPDATE/DELETE the same row of the target table multiple times. Refine the ON clause to ensure a target row matches at most one source row, or use the GROUP BY clause to group the source rows.
Warning: Null value is eliminated by an aggregate or other SET operation.,Source=.Net SqlClient Data Provider,SqlErrorNumber=8672,Class=16,ErrorCode=-2146232060,State=1,Errors=[{Class=16,Number=8672,State=1,Message=The MERGE statement attempted to UPDATE or DELETE the same row more than once. This happens when a target row matches more than one source row. A MERGE statement cannot UPDATE/DELETE the same row of the target table multiple times. Refine the ON clause to ensure a target row matches at most one source row, or use the GROUP BY clause to group the source rows.,},{Class=0,Number=8153,State=1,Message=Warning: Null value is eliminated by an aggregate or other SET operation.,},],'
When you encounter an error like this, it can be caused either by problems in the stored procedure or by overlapping runs of pipelines.
- To check whether overlapping pipeline runs is the cause, you can run the find_adf_overlap.sql script on the Analytics database. The output of the script should show if there have been any overlapping runs.
Whether there is overlap or not, it is recommended that you try to run the Factory reset pipeline to see if that resolves the issue.
- The Factory reset pipeline cleans all data from staging, dimension and fact tables, so if there are any duplicates causing issues, they should be removed by running the Factory reset.
- Once the Factory reset is finished, you need to wait for the next Scheduled run to finish to see if the issue has been resolved. If not, please contact LS Retail support for further assistance on solving the issue of duplicate lines.
Note: The Factory reset pipeline deletes all data from staging-, dimension- and fact tables and re-fetches all data from LS Central. Therefore, it is very important to plan this very well so that it does not have a negative effect on the LS Central system. When running the Factory reset pipeline, you must make sure that there is no other pipeline active and you must also disable the Scheduled run trigger to prevent the pipelines from overlapping each other. It is also recommend that users scale their Azure Analytics database to a higher service tier while running the Factory reset to complete it faster.
If you want to increase the speed of running the Scheduled Run pipeline or you need to reset the data warehouse, the most effective way to do that is to increase the pricing tier of your Analytics database from the S2 that we suggest in the training to S3, S4, or even higher.
Increasing the pricing tier will, like the name implies, increase the monthly cost of the database. But if you scale up for one day and then scale down again, you only pay the increased monthly price for the one day and lower the pricing tier cost for all the days in the database that are set to that tier.
You can also decrease the pricing by lowering the pricing tier, but this will result in the pipelines taking longer to run because of the decreased number of DTU's available in the database.
To change the pricing tier, log in to the Azure portal and find your SQL database. In the essentials section you should click the pricing tier name.
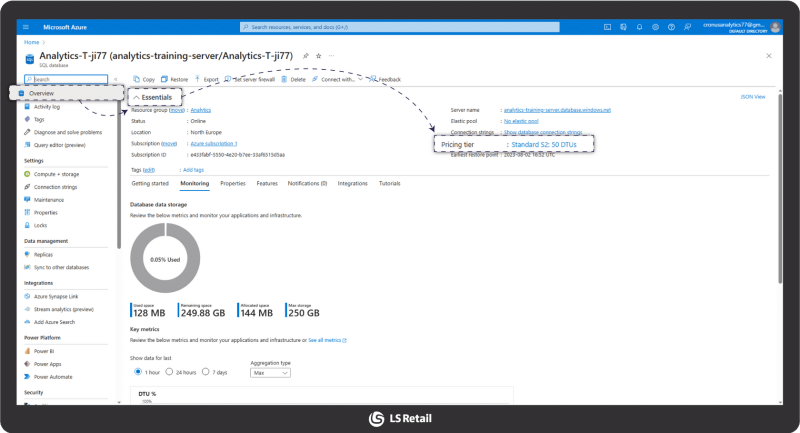
This will open the Service and Compute tier page. From here, you can slide the DTUs slider to the right to increase the service tier and to the left to decrease it. Press apply to confirm changes.
Another type of error that can occur in the pipelines is missing column error.
Database changes in the LS Central source database need to be investigated when these errors occur. Changes in the database do not occur often unless the LS Central environment is updated. In most cases you can continue to run Analytics without making any changes.
If there are breaking changes in the LS Central (for example, columns removed) you need to run the Factory reset pipeline.
- Sometimes a change in the LS Central database can produce an error much later in Analytics if you run the populate query base pipeline in the ADF.
- If you run the populate query pipeline, you update the metadata for LS Central tables, but there are no changes made to the staging tables in the Analytics database.
- This would result in an error, for example, if a new column was added to a table in LS Central, which is then not added to the staging table in Analytics.
If the change is related to a column that is not used in the Analytics warehouse, you can trigger the Factory reset pipeline as described above.
- The factory reset pipeline recreates the staging tables based on the new metadata from LS Central.
If the changes in LS Central database affect columns used in Analytics
- you need to look into all procedures using the column, and make the necessary changes.
If issues in the pipelines have been resolved by the previous steps then it is likely that refreshing the semantic model in Power BI desktop or service is enough for the report to be populated with data and you can refer to the Power BI section.
Note: If it does not please continue to the section that fits your LS Central source platform in the next chapter to check whether the data warehouse tables have been populated with data.
If you have LS Central on-prem, and your ADF is running without any errors, you should start by checking whether there is any data in the fact tables.
Each fact table depends on multiple tables, but most of them have one main staging table and then multiple dimension tables. Some of the more complex fact tables depend on multiple staging tables, f.x. the FactSalesPosted table depends on three staging tables.
In our example we will use the [DW].[fPOSPayments] table.
The first step is always to check whether there is any data in the fact table. The best way to do this is to login to the Analytics database, either with SQL Server Management Studio or Azure data studio, and perform the following query: “”.
SELECT *
FROM [DW].[fPOSPayments]
If the data in the table looks correct, the problem is in Power BI. Please go to the Power BI chapter.
If there is no data in the fact table, you need to trace your way back to the source tables for the fact table.
First we need to find which staging and dimension tables are used. If you need help with identifying them you can expand and read through the next section.
Each fact and dimension table depends on one or more tables in the staging and/or dimension tables. The best way to find out which table/s they depend upon is to look at the procedure in the Analytics database. All fact and dimension tables have a procedure with a similar name, and that procedure is responsible for merging and updating data in the corresponding table.
Near the top of the procedure, you should find a section which is performing a count from a staging table (in our case [stg$Trans_ Payment Entry]) to check whether there is any new data to process. The table used in this count statement is the main staging table for this fact table.
If you scroll through the procedure, you will find a number of common table expression (CTE link to https://learn.microsoft.com/en-us/sql/t-sql/queries/with-common-table-expression-transact-sql?view=sql-server-ver16) statements which are used to simplify the MERGE statement at the end of the procedure. To find all tables the procedure is dependent upon, simply go through the procedure and find all table names that are used.
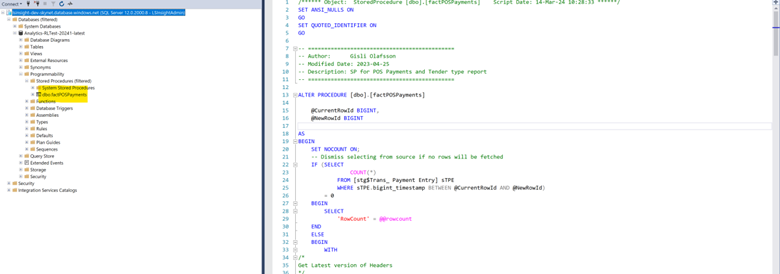
In the image below you can see three CTE statements (tTransactionHeader ,tCompanies and tLocation), each using a different staging or dimension table.
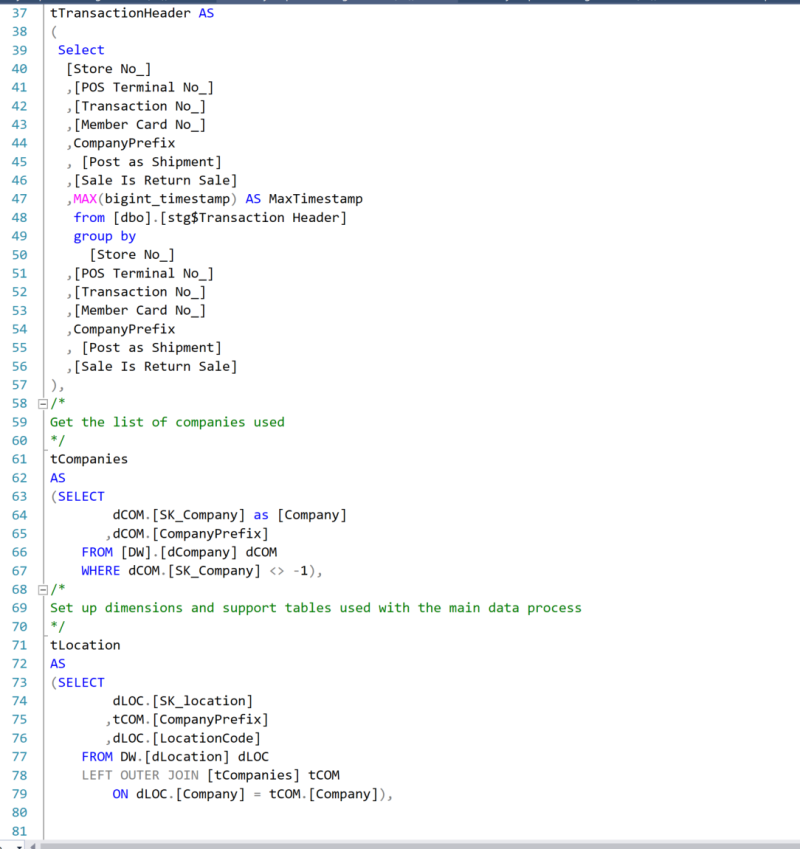
In our case we find that the main staging table is the [stg$Trans_ Payment Entry] table.
Start by performing
SELECT *
FROM [stg$Trans_ Payment Entry]
in the Analytics database and verify that there is data in the staging table.
If the staging table is empty or missing, there is probably an issue with the Query base in Analytics. The query base is generated during the Initial load pipeline. It uses metadata from the LS Central database to determine which tables and columns are present and then uses that information to generate what we refer to as the query base. The query base is a table in the Analytics database which contains SQL statements used to query the LS Central database as well as SQL snippets to create and drop the staging tables in the Analytics database.
Analytics uses the [dbo].[LSInsight$SourceTablesMap] table to determine which tables should be copied from LS Central to the staging area. So if the staging table is missing or empty, you need to check this table. Here is a query for our example:
SELECT *
FROM [dbo].[LSInsight$SourceTablesMap]
WHERE [SourceTableName] = 'Trans_ Payment Entry'
The query should result in a single row which looks like this.
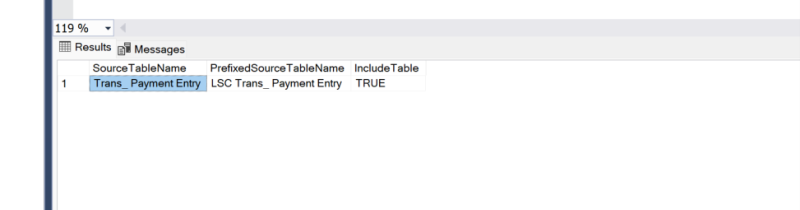
If there is no row for the table, or the IncludeTable value is set to FALSE, you need to update the [Analytics$SourceTablesMap] table. This can be achieved by either using the Add or Delete Source Tables pipeline in the ADF or by creating an INSERT/UPDATE statement to set the correct data in the [Analytics$SourceTablesMap] table. When the source table map is updated, run the Factory Reset pipeline in the ADF .
Another issue that could come up is that the company your data is in, is not being added to the Analytics datawarehouse. To see if the company is registered in the [Analytics$Companies] table in Analytics.
If the company is missing from the table, you can use the Add or Delete Companies pipeline in ADF to add the missing company. Once the company has been added, you can trigger the Scheduled Run pipeline to get your data.
Once the fact tables have been populated a refresh of the semantic model in Power BI desktop or service should be enough for the report to be populated with data and you can refer to the Power BI section.
Check data in tables - LS Central source is in SaaS
If you have LS Central SaaS and are having issues with the data delivery, we recommend that you first check the prestaging tables to see whether the replication jobs are working. That is, replicating data from LS Central SaaS to the prestaging tables.
Lets use the [DW].[fPOSPayments] fact table as our example of missing data. To find out which prestaging table is behind the fact table, you can use the method described in the “What are the source tables?” chapter to find the staging table. With the staging table name, it is easy to find the correct prestaging table. In our example the staging table is [stg$Trans_ Payment Entry] and therefore the prestaging table is:
SaaSReleaseTest$LSC Trans_ Payment Entry$5ecfc871-5d82-43f1-9c54-59685e82318d2
SaaSReleaseTest is the name of the test company in our LS Central installation. Your prestaging table name should reflect your company name.
The LSC prefix on the table name is removed in the staging table name since it is not needed. Please note that not all tables will have this LSC prefix, f.x. all the base tables in Business Central.
Start by performing
SELECT *
FROM [<Company>$LSC Trans_ Payment Entry$5ecfc871-5d82-43f1-9c54-59685e82318d
in the Analytics database and verify that there is data in the prestaging table.
If all the data is in the prestaging table, go to the Troubleshooting Data in Analytics for further investigation.
If the prestaging table is empty or missing a lot of data, the problem is somewhere in the replication process from the SaaS instance into the Analytics prestaging tables. Expand the section below if you need assistance in troubleshooting the replication process.
There are four jobs (five if you have the Hotels extension) that handle the data replication.
• INS_ACTIONPRELOAD
• INS_ACTIONS
• INS_NORMAL_FULL
• INS_NORMAL_COUNT
• INS_NORMAL_HOTEL
If this problem occurs during the initial setup of Analytics, please make sure that the onboarding directions have been followed. It is very important that the INS_ACTIONPRELOAD job is allowed to finish before any other job was started.
If all steps in the onboarding guide were followed and still there is missing data, we need to see if all the jobs are running successfully. On your scheduler server, open the Data Directory Configuration tool, select the Debugging tab and open the Job Monitor and the Database and WebSrv debugging windows.
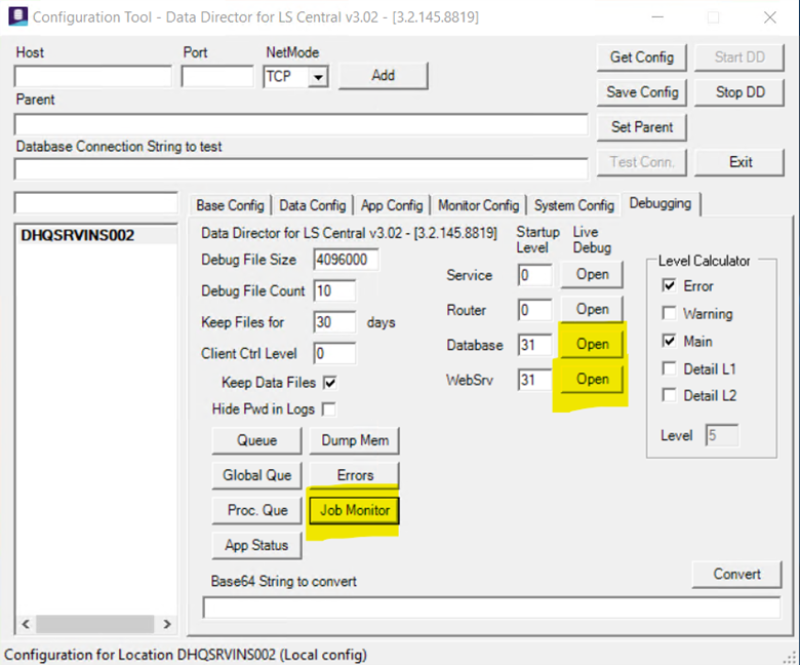
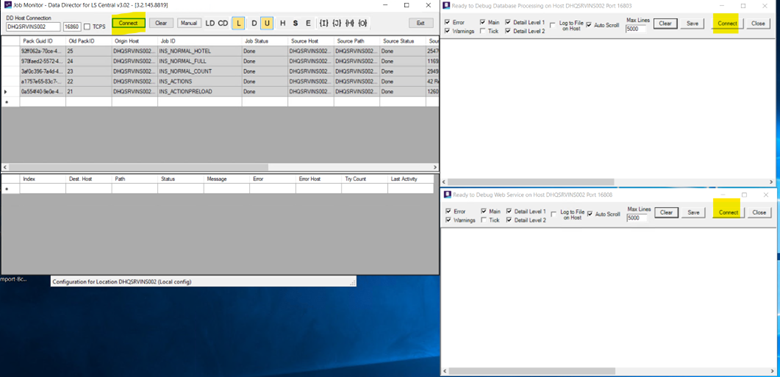
You will need to press the Connect button in all windows to start the debugging. In the image above you can see what the Job Monitor should look like if all jobs ran successfully.
In our case we are tracing the data for the Trans_ Payment Entry table, so we need to find which job handles the replication for this table. The quickest way to find this is by going into the Scheduler Job List in LS Central and look at the sub-jobs in each of the jobs. In our case, the Trans_ Payment Entry table is in the INS_NORMAL_COUNT job.
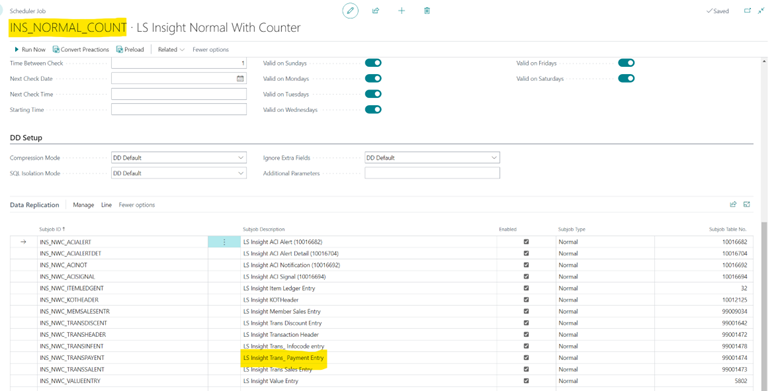
When you have found the correct job, press the “Run Now” button in the scheduler job and then monitor the process in the Job Monitor and debugging windows. You should first see a lot of logs in the WebSrv debugging window, and then once all the data has been read from the SaaS environment the database debugging window should show the Data Director inserting data into the prestaging tables in the Analytics database.
Sometimes the Data Director seems to lose the connection to the SaaS environment. In those cases all jobs are idle and nothing is showing in the debugging windows. There are 2 steps that you can try to fix the issue.
First you can press the Queue button in the Data Director Configuration tool. There you should see a list of jobs that are waiting. Try pressing the Reset button for the process, that should force the Data Director to reconnect to the SaaS environment and hopefully kickstart the jobs in the queue.
If that does not work, you need to restart the Data director using the following steps:
- Cancel all Jobs
- Stop Data Director service
- Deleted all jobs in the Work Folder - Default location: C:\ProgramData\LS Retail\Data Director\Work)
- Start Data Director service
- Open the Job Monitor
- Open the Web Server Debugger
- Open the Database Debugger
- Triggered the Job to Run
Once the job has run you should have data in the prestaging tables.
Once you have made sure the data has been replicated to the prestaging tables you can go ahead and run the Scheduled run pipeline and check whether the fact and dimension tables have been populated correctly as explained in the chapters above. When the fact tables have been populated a refresh of the semantic model in Power BI desktop or service should be enough for the report to be populated with data and you can refer to the Power BI section.
Refresh Power BI and check for filters
If Scheduled run or Factory reset pipeline was run successfully and you have verified that there is data in tables that were previously empty, you can refresh the Power BI, either manually in Power BI desktop or Power BI service or schedule an automatic refresh of the semantic model.
Once the report has been refreshed it should contain the data that was missing.
If you have done all this and the data still does not seem right, you should check if you have any filters set on the report pages or visuals that are filtering the data in unexpected ways. If you find filters that you do not want, you can simple remove them and more data will be displayed.
If missing data is not caused by filters then please register your issue in the support portal, stating the steps you have taken to troubleshoot the issue and we will assist you.